Elastic Stack è uno strumento potente per favorire un processo di trasformazione digitale fluido ed efficace della tua azienda, garantendo l’osservabilità degli applicativi e le relative performance.
Le modalità di adozione della soluzione dipendono dalle caratteristiche dei propri sistemi IT e dalle esigenze specifiche.
Capiamo quali sono i passi fondamentali da compiere per adottare questo strumento in azienda.
Definire la modalità di installazione di Elastic Stack: on-premise o in cloud
Elastic Stack raccoglie una grande mole di informazioni, tra cui anche dati sensibili che necessitano dell’opportuna protezione di sicurezza.
Innanzitutto, è necessario definire se si vuole distribuire Elastic Stack in un ambiente on-premise o in cloud. CIO e responsabili IT dovrebbero scegliere l’ambiente ottimale considerando alcuni elementi, quali l’elasticità, la sicurezza, i costi, l’affidabilità e la copertura geografica.
- On-premise è una scelta che tipicamente viene fatta per motivi legali, al fine di avere una maggiore governance dei dati, che vengono conservati in data center proprietari, detenuti e controllati privatamente;
- In cloud vengono invece noleggiate le risorse dei data center da un service provider esterno in cui vengono depositate le informazioni.
L’installazione in cloud permette di ottenere una maggiore scalabilità e flessibilità, potendo aggiungere o rimuovere liberamente le risorse dall’infrastruttura in base alle esigenze applicative e velocizzando i tempi di avvio e configurazione. Quest’ultimo è un elemento da non sottovalutare se si considera che oggi una configurazione lenta può ritardare l’introduzione di nuovi prodotti sul mercato, ridurre la produttività e avere un impatto negativo sull’esperienza utente.
Inoltre, gestire l’infrastruttura, il networking e la manutenzione di data server proprietari richiede tempo e risorse da dedicare, che potrebbero essere impiegati in progetti a maggior valore per l’azienda.
Dall’altra parte, la sicurezza sta diventando sempre più una priorità per molte aziende, per cui l’installazione on premise garantisce un maggiore controllo e responsabilità delle informazioni. Non dimentichiamoci però che installando Elastic Stack in cloud è possibile beneficiare delle innumerevoli risorse dedicate alla sicurezza messe a disposizione dai relativi fornitori di servizi, che garantiscono un pronto intervento affinché le informazioni rimangano al sicuro e i tempi di inattività vengano ridotti al minimo.
La scelta tra on-premise e cloud è in definitiva aziendale, basata sulla roadmap intrapresa: occorre considerare i diversi costi di gestione, dal momento che la modalità on-premise necessita di risorse che conoscano approfonditamente Elastic Stack.
A seconda delle esigenze sopracitate, nulla vieta di adottare un approccio ibrido, raccogliendo le informazioni in un unico stack proprietario e distribuendo i dati non sensibili in infrastrutture in cloud.
Uniformare i vari log in un formato comune
Quando si introduce uno strumento che prevede un’attività di log management, ci si ritrova inevitabilmente con log scritti in formati diversi da vari fornitori, che potrebbero fare delle resistenze nel cambiare il formato per uniformarlo. In questi casi, l’adozione di Elastic Stack deve prevedere un lavoro preventivo di analisi sintattica dei log (parsing) per capire come sono costruiti. Dopodiché le informazioni devono essere estratte ed elaborate, trasformandole in dati uniformi.
Logstash è lo strumento di Elastic Stack che assolve a questa funzione, preparando i dati dinamicamente a prescindere dal loro formato o dalla loro complessità: mentre i dati passano dalla fonte all’archivio, i filtri Logstash analizzano ogni evento e creano una struttura verso cui convergere per potenziare la capacità di analisi grazie a un formato comune.
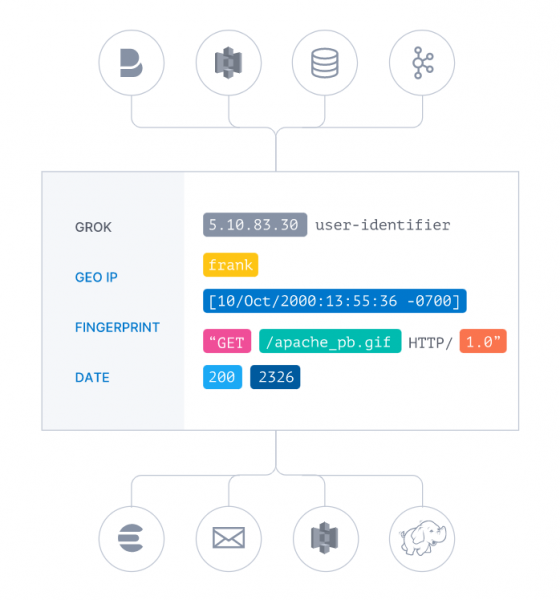
In questa fase, consigliamo di lavorare su approssimazioni successive, cioè evitando di portarsi in casa tutti i dati e procedendo seguendo alcuni step, quali:
- Focalizzazione iniziale solo sulle metriche e i dati che si vogliono avere.
- Raccolta delle informazioni da tutte le infrastrutture e dai servizi dei fornitori per arrivare ad un formato comune.
- Reiterazione dei due punti sopra prendendo in considerazione nuovi dati da importare per arrivare ad altre informazioni utili.
Scarica il caso studio di un Gruppo Bancario
Dimensionamento preventivo per allocare le risorse
Come abbiamo visto, Elastic Stack raccoglie log e altre informazioni da tanti sistemi diversi, per cui tra i primi passi da fare se si vuole introdurre la soluzione sarà importante stimare una valutazione del possibile dimensionamento dei dati.
Uno dei motivi per cui suggeriamo di procedere a step successivi è anche per questo: avere una stima preventiva da valutare è molto difficile perché i dati raccolti potrebbero essere veramente tantissimi. Per un nostro cliente, per intenderci, raccogliamo oltre 30 giga al giorno solo di log.
In fase iniziale, quando si vanno a raccogliere i log, sarà quindi importante cercare di capire a quanto ammonta il dimensionamento dei dati, facendo una stima e tarando le impostazioni del sistema e lo spazio su disco che poi verrà allocato allo stack, in compatibilità con i livelli di retention attesi.
Infatti, nulla vieta di utilizzare meno spazio su disco a fronte però di una retention più corta dei dati, che potrebbero essere visibili per un periodo inferiore a seconda delle esigenze.
Come adottare Elastic Stack: il nostro approccio
I nostri esperti IT valutano caso per caso la modalità più idonea per l’installazione di Elastic Stack, personalizzando la soluzione in base alle specifiche esigenze tramite un servizio gestito a 360°, che prevede anche il supporto nella scrittura dei log e la relativa normalizzazione per renderli più facilmente assimilabili dal sistema.
Vuoi sapere di più su come funziona nella pratica Elastic Stack? Guarda la nostra demo gratuita on demand:

 Amazing
Amazing Good
Good Bad
Bad Meh
Meh Pff
Pff