Con l’aumentare della complessità dei moderni ambienti IT, la capacità di un’architettura software di rendersi monitorabile e controllata (observability) diventa un attributo sempre più strategico da costruire per garantire il livello di servizio richiesto dal mercato. Tuttavia, per ottenere un sistema altamente osservabile è necessario raccogliere una grande mole di informazioni provenienti da molteplici fonti (server, strumenti, applicazioni, log, etc.), accentrarle in un unico punto e metterle in correlazione tra loro. Capiamo come la soluzione open source Elastic Stack permette di controllare sistematicamente un’architettura integrando qualsiasi sistema e aggregando log, metriche e tracing.
I tre pilastri dell’osservabilità: log, metriche e tracing
Il progressivo passaggio da architetture monolitiche verso applicativi distribuiti rende sempre più urgente adottare strumenti per il controllo e il monitoraggio efficiente dei propri sistemi IT. L’osservabilità di un ambiente IT, però, non è qualcosa che si può semplicemente accendere e far funzionare, ma è un attributo del sistema che si deve costruire per comprendere il comportamento di un’architettura e ottenere informazioni significative sulle prestazioni degli applicativi, nonché per identificare facilmente gli errori.
L’osservabilità di un sistema applicativo è tipicamente basata su tre pilastri:
- Log applicativi, ossia file contenenti informazioni sugli eventi che sono avvenuti in un’applicazione in un certo momento. Il loro formato spesso non è standard e sono sparsi su diversi macchine/container che ospitano gli applicativi;
- Metriche, ossia indicatori che mostrano come sta funzionando nel tempo un’applicazione e l’infrastruttura che la ospita. Le metriche sono in grado di evidenziare un problema, ma non danno mai indicazione su quale sia la causa. Si pensi, per esempio, a una macchina con un carico di CPU elevato o a un alto numero di richieste al secondo su un’API o a lunghi tempi di risposta: tutte queste metriche evidenziano che c’è un problema, ma non identificano la relativa causa di origine. Di conseguenza, le metriche hanno poco valore se non correlate con altre informazioni, come ad esempio i log;
- Tracing (APM), ossia dati sulle performance di un applicativo ottenuti tipicamente strumentando il codice in maniera automatica o manuale. Questi dati danno un’indicazione ancora più profonda e immediata su come si sta comportando un applicativo e dove si collochino eventuali colli di bottiglia, evitando operazioni manuali dispendiose.
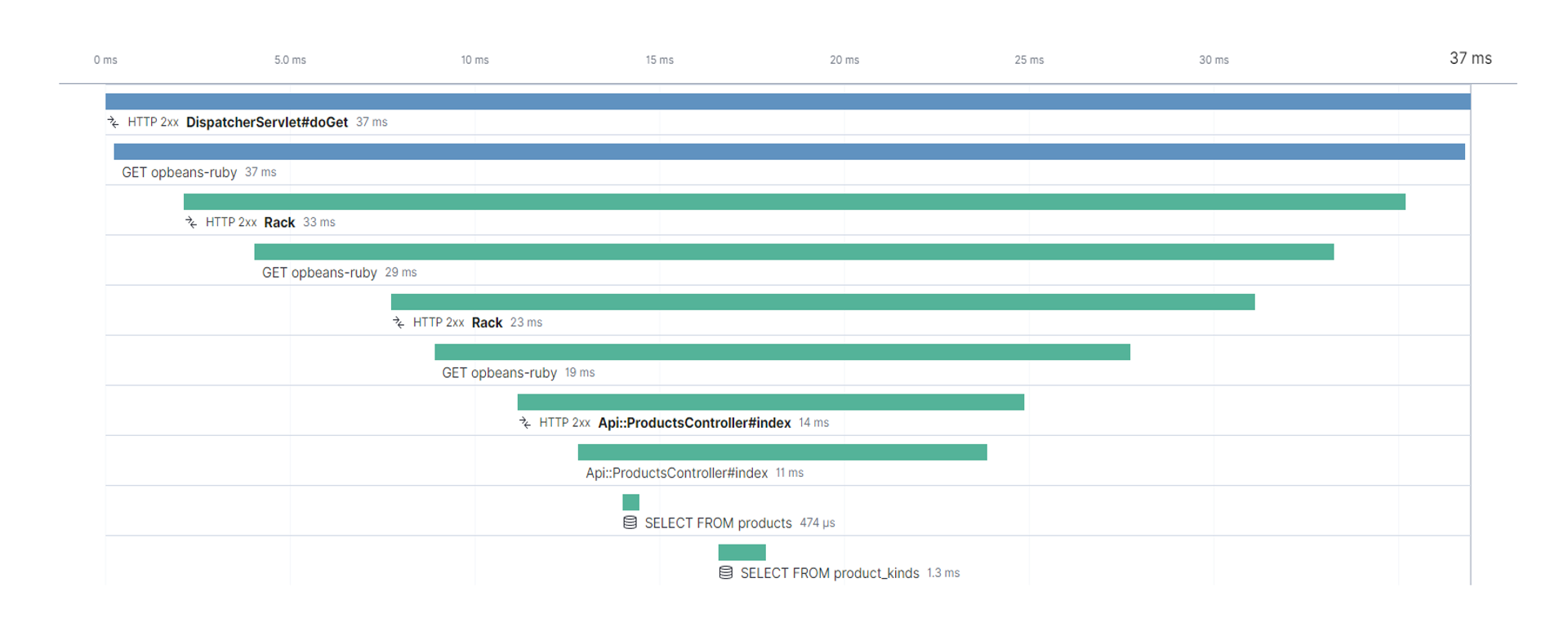
Nella figura sottostante vediamo un esempio di soluzione di tracing estratto da Elastic Stack, in cui sono rappresentati due microservizi (blu e verde) in comunicazione tra loro. A fronte di una chiamata da parte del primo microservizio, il grafico mostra la suddivisione delle richieste al servizio sottostante: informazione molto utile che mette in evidenza, per esempio, come la chiamata verso il database (SELECT) ha occupato una parte minima del tempo rispetto al totale in alto, informandoci immediatamente che probabilmente il collo di bottiglia non sarà a livello di comunicazioni verso il database.
Scarica il caso di Dolomiti Superski
Elastic Stack DEMO: come funziona la soluzione per il monitoraggio degli applicativi
Costruire un sistema di observability significa integrare e aggregare i dati per rendere le informazioni facilmente accessibili tramite specifiche dashboard.
Elastic Stack offre una soluzione (open source) sui tre pilastri (log, metriche e tracing) attraverso diversi strumenti: filebeat, metricbeat e APM agent, che uniti a Elasticsearch, Logstach e Kibana costituiscono Elastic Stack.
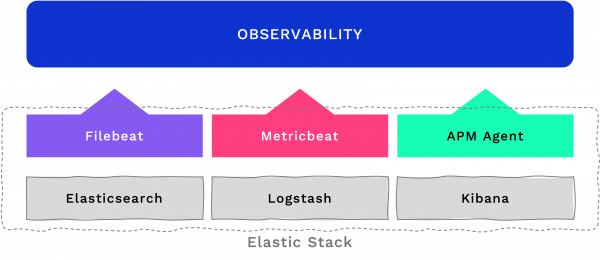
Capiamo meglio le funzioni di ciascuno di questi strumenti.
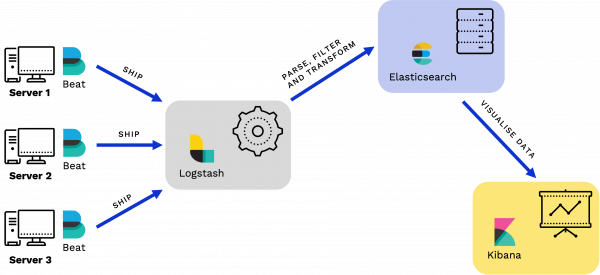
Supponiamo di avere 3 server su cui andiamo a installare i beat: questi vanno a recuperare le informazioni che ci servono e le consegneranno verso Logstash, componente che fa da ricettore di tutti questi dati, li accoda, li elabora e li trasforma normalizzandoli. Le informazioni normalizzate vengono poi trasferite su Elasticsearch, motore NoSQL che permette di memorizzare queste informazioni e ricercarle in modo molto veloce. Le informazioni vengono poi rese fruibili a livello utente da Kibana, strumento per la dashboard di visualizzazione dei dati.
Scarica il caso di un Gruppo Bancario
Observability: i vantaggi di Elastic Stack
Grazie alla funzione di aggregazione, elaborazione, archiviazione e analisi dei dati, Elastic Stack diventa uno strumento potente per ottenere l’observability del tuo ambiente IT, garantendo:
1. La correlazione dei dati
Raccogliendo fisicamente le informazioni di tutti gli applicativi in un unico punto, è possibile correlare i dati e semplificare l’individuazione della causa di un problema di un applicativo.
2. Il contenimento dei costi operativi
Con lo stack Elastic i costi operativi vengono ridotti non solo dal punto di vista della licenza –che nella versione base senza funzionalità avanzate, è open source e gratuita –, ma soprattutto perché sui tre pilastri dell’observability agiamo con un unico strumento, riducendo i tempi di apprendimento e di adozione della soluzione.
3. L’alerting unificato
Accentrando i dati in un unico punto, è possibile impostare degli alert al verificarsi di qualunque tipo di evento che si è registrato in Elastic Stack. Potrebbe essere un alert più interessante a livello business, come una SLA non rispettata, o un alert più utile agli sviluppatori, come ad esempio al verificarsi di un log che tipicamente genera un problema, aumentando la proattività nell’intervento prima che si verifichino disservizi.
Scopri di più su come funziona Elastic Stack guardando la nostra demo on demand gratuita:

 Amazing
Amazing Good
Good Bad
Bad Meh
Meh Pff
Pff